
Hay una práctica silenciosa en el sector público mexicano y latinoamericano que distorsiona buena parte de la evaluación de programas: tratar a la Matriz de Marco Lógico (MML) y a la Matriz de Indicadores para Resultados (MIR) como plantillas que se llenan, no como instrumentos analíticos que se construyen.
Cuando una MIR se llena, mide la teoría del programa. Cuando se construye, mide la realidad del programa. La diferencia, en términos presupuestales y de política pública, no es de matiz: es de toda la utilidad del ejercicio.
Lo que la MML debía hacer
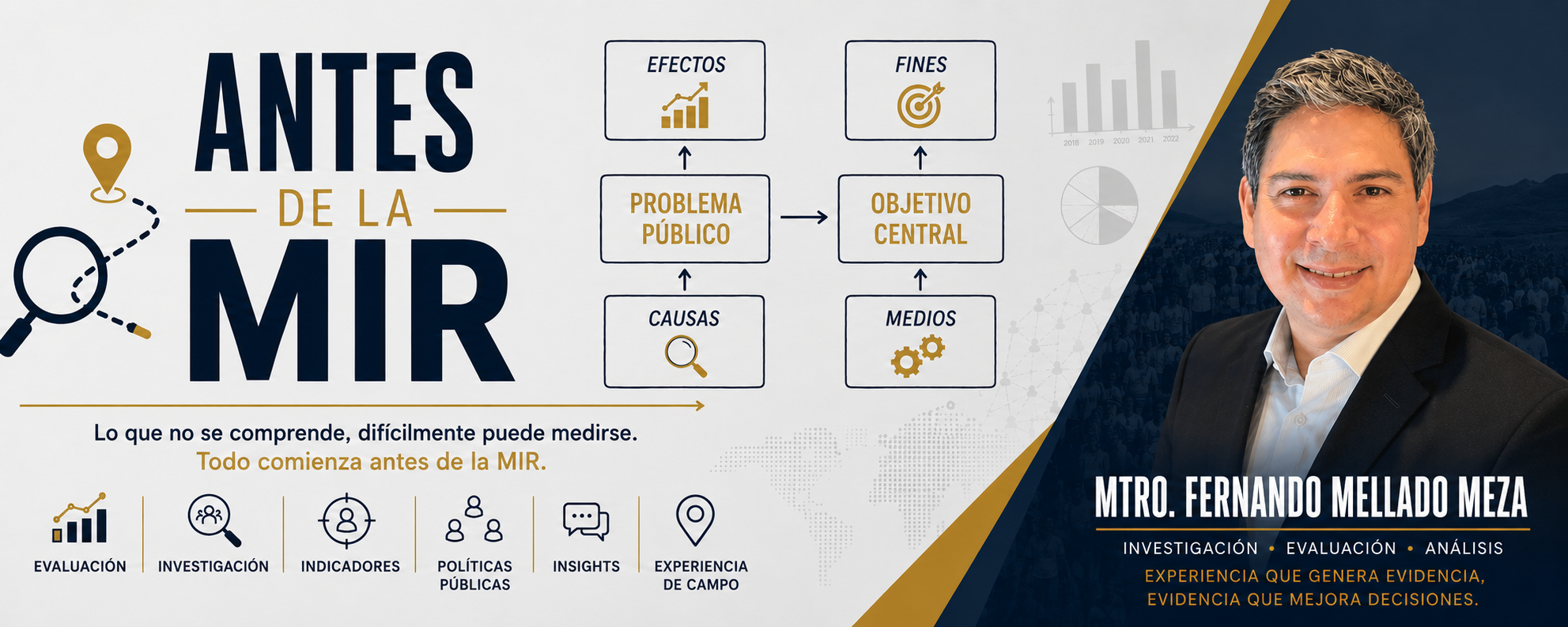
La MML, diseñada originalmente como herramienta de aprendizaje organizacional, propone una lógica vertical: actividades → componentes → propósito → fin. Cada nivel debe responder por qué el anterior es necesario. La MIR, su derivada operativa en México, formaliza esa lógica con indicadores, medios de verificación y supuestos.
Bien aplicada, esta cadena obliga a tres cosas: a hacer explícita la teoría de cambio del programa, a buscar evidencia de que esa teoría sostiene sus supuestos, y a definir qué se observará para corregir el rumbo si la teoría falla.
Lo que la MML hace en la práctica
En la mayoría de los casos que pasan por evaluación, la MIR se rellena después de que el programa está diseñado, no antes. Los indicadores se eligen por disponibilidad de datos —lo que ya se mide y se reporta— en lugar de por relevancia conceptual —lo que el cambio que se busca implicaría observar. Los supuestos se redactan como formalidad. Los medios de verificación se eligen por costo bajo, no por validez.
El resultado es predecible: una matriz que cumple con el requisito formal y que mide, con consistencia, lo que la teoría del programa dice que debería estar pasando — independientemente de si está pasando o no.
Por qué pasa esto
No por mala fe ni por incompetencia. Por tres incentivos estructurales.
Primero, los tiempos. Las MIR se actualizan al ritmo del calendario presupuestal, no al ritmo del aprendizaje del programa. Cuando hay tres semanas para entregar, “construir” no cabe; “llenar” sí.
Segundo, la auditoría. Si los indicadores miden algo que el programa controla directamente, se reportan en verde y la auditoría no pregunta más. Si miden lo difícil —el cambio real en la población— los rojos son inevitables, y el rojo en una MIR cuesta caro en la conversación presupuestal del siguiente ciclo.
Tercero, el ecosistema de evaluadores. Una parte significativa del gremio se formó bajo el paradigma del cumplimiento, no del aprendizaje. Saben llenar bien; no siempre saben dónde se rompe la teoría del programa que la matriz pretende representar.
Qué hacer en vez de llenar una «plantilla MML»
No se trata de tirar la MML; el marco es útil cuando se usa para lo que fue diseñado. Lo que cambia es la pregunta inicial. En vez de “¿qué indicadores tenemos disponibles para los componentes de este programa?”, la pregunta correcta es “¿qué tendría que estar pasando en la población, en la operación y en el contexto para que la teoría de este programa sea cierta — y qué evidencia mínima necesitaríamos para distinguir entre ‘está funcionando’ y ‘parece funcionar’?”.
Esa pregunta, mal contestada, produce indicadores blandos pero al menos honestos. Bien contestada, produce un programa que se corrige solo.
Tres preguntas antes de la MIR
Antes de dar por bueno cualquier ejercicio de marco lógico, vale la pena pasar por tres filtros.
Uno. Si el indicador de Propósito sale verde tres años seguidos y el programa no se elimina ni se replica, ¿qué nos dice el indicador? Si la respuesta es “nada útil”, el indicador mide cumplimiento, no cambio. Recordemos que el indicador de propósito es el indicador que mide el logró del objetivo central.
Dos. ¿Quién, fuera del equipo del programa, podría reproducir la medición con los medios de verificación definidos? Si la respuesta es “nadie”, la matriz funciona como reporte interno, no como instrumento público. Los medios de verificación siempre deben ser públicos y al alcance de todos.
Tres. ¿Qué supuesto, si falla, invalida toda la teoría del programa — y cómo sabríamos si está fallando? Si no hay respuesta clara, el programa está operando con un punto ciego estructural. Los supuestos deben tener una ligera probabilidad de ocurrencia pero no la suficiente para garantizar que ocurrirá, ya no sería un supuesto sino un hecho por ocurrir que debería tratarse en el diseño.
La MML no es el problema. Tratarla como plantilla, sí. La diferencia entre evaluación que sirve y evaluación que ocupa espacio es esa pregunta inicial — y la disposición a sostener una conversación incómoda con quien diseñó el programa si la respuesta no aterriza.
Si tu programa, secretaría o unidad de evaluación está cargando una MIR que ya nadie cree, esa es una buena conversación para retomar.
Este blog se llama Antes de la MIR porque ahí — antes de cargar la plantilla — es donde se gana o se pierde la utilidad de cualquier evaluación. Aquí publico una entrada cada quincena en esa misma lógica: política pública con investigación de fondo, sin atajos metodológicos. Si esta conversación es relevante para tu unidad, programa o secretaría, escríbeme directamente.
Deja un comentario